
http协议与服务
HTTP协议与服务
以下为学习过程中的极简提炼笔记,以供重温巩固学习
学习准备
准备工作
在AJAX技术的学习中,Axios原理及node.js与webpack中都有涉及到HTTP协议,现为专题巩固
学习目的
HTTP协议及其组成
初识
HTTP(hypertext transport protocol)协议;中文叫超文本传输协议
- 是一种基于TCP/IP的应用层通信协议
- 这个协议详细规定了
浏览器和万维网服务器之间互相通信的规则。 - 互联网应用最广泛的协议之一
协议:双方必须共同遵从的一组约定
协议中主要规定了两个方面的内容
- 浏览器/客户端:用来向服务器发送数据,可以被称之为请求报文
- 服务器/服务端:向客户端返回数据,可以被称之为响应报文
报文:可以简单理解为就是一堆字符串
- 通过 fiddler 抓包查看http协议,类似浏览器调试的效果
请求报文的组成
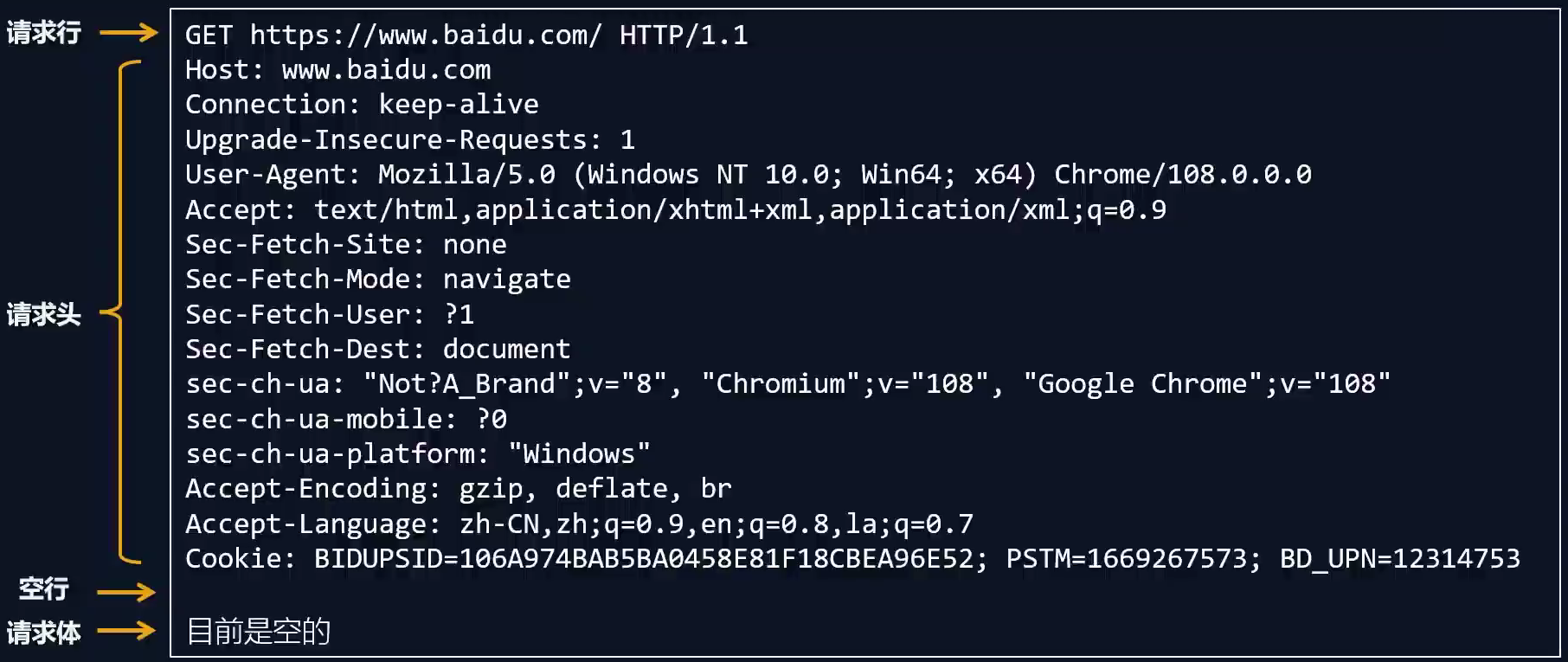
- 请求行
- 请求头
- 空行
- 请求体
HTTP 的请求行

请求方法(get、post、put、delete等)
请求方法 解释 GET 主要用于获取数据 POST 主要用于提交数据 PUT / PATCH 主要用于更新数据 DELETE 主要用于删除数据 HEAD 主要用于获取响应头 OPTIONS 主要用于获取支持的请求方法 CONNECT 主要用于建立连接隧道 TRACE 主要用于追踪请求的传输路径 请求 URL(统一资源定位符Uniform Resource Locator,本质是一个字符串,用于定位服务器上的资源)
举例:http://www.baidu.com:80/index.html?a=100&b=200#logo
第一部分:http: 协议(https、ftp、ssh等)
第二部分:主机名:如 www.baidu.com 域名,也可以是IP地址
80 端口号 (端口号在某些情况下可以省略)
/index.html 路径,定位服务器上的资源
a=100&b=200 查询字符串,键名键值对的结构,&符作分割
#logo 哈希(锚点链接)

- HTTP协议版本号
版本号 发布时间 1.0 1996年 1.1 1999年 2 2015年 3 2018年
HTTP 请求头
- 请求头由一系列键值对组成
- 格式:『头名:头值』
常见的请求头有:
| 请求头 | 解释 |
|---|---|
| Host | 主机名 |
| Connection | 连接的设置 keep-alive(保持连接);close(关闭连接) |
| Cache-Control | 缓存控制 max-age = 0 (没有缓存) |
| Upgrade-Insecure-Requests | 将网页中的http请求转化为https请求(很少用)老网站升级 |
| User-Agent | 用户代理,客户端字符串标识,服务器可以通过这个标识来识别这个请求来自哪个客户端 ,一般在PC端和手机端的区分,可区分浏览器平台和版本号 |
| Accept | 设置浏览器接收的数据类型 |
| Accept-Encoding | 设置接收的压缩方式/浏览器支持的压缩方式 |
| Accept-Language | 设置接收的语言 q=0.7 为喜好系数,满分为1 /浏览器支持的语言 |
| Cookie | 后面单独讲 |
参考:https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers
HTTP 的请求体
请求体内容的格式是非常灵活的
- (可以是空)=> GET请求
- (也可以是字符串,还可以是JSON)=> POST请求
- 只要是与后端协商好接口文档/接口协议即可
- 项目中使用得比较多的形式是:JSON形式
- 服务器从请求体取出数据,再转成对象处理
例如:
- 字符串:
keywords=手机&price=2000 - JSON:
{"keywords":"手机","price":2000}
响应报文的组成
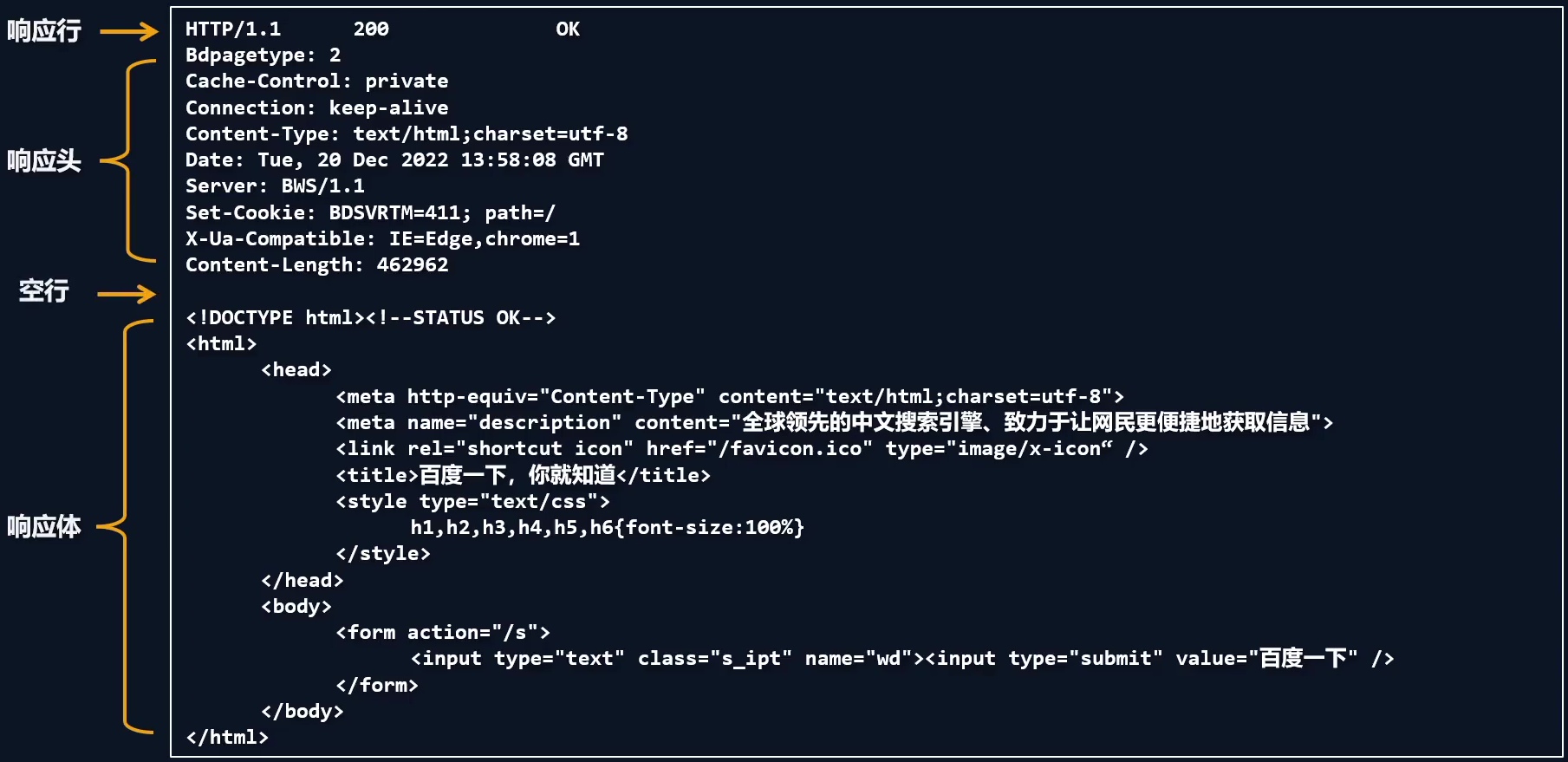
响应行
HTTP/1.1:HTTP协议版本号
响应状态码是一个三位的数字,用于标识响应的结果状态
- 200: OK 请求成功响应状态码
- 403: Forbidden 禁止请求
- 404: Not Found 找不到资源
- 500: Internal Server Error服务器内部错误
还有一些状态码,参考:https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Status
状态码五大类:
状态码 含义 1xx 信息响应 2xx 成功响应 3xx 重定向消息 4xx 客户端错误响应 5xx 服务端错误响应 响应状态描述:
本质:字符串
性质:响应状态码和响应字符串关系是一一对应
200: OK 请求成功响应状态码
403: Forbidden 禁止请求
404: Not Found 找不到资源
500: Internal Server Error服务器内部错误

响应行 响应头
Cache-Control:缓存控制 private 私有的,只允许客户端缓存数据 Connection 链接设置 Content-Type声明响应体格式和字符集:设置响应体的数据类型以及字符集,如 text/html;charset=utf-8 ,其中 响应体为html,字符集 utf-8 Content-Length:响应体的长度,单位为字节 Date:响应时间 server:服务器使用的技术查响应头:https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers
空行
响应体
- 响应体内容的类型是非常灵活的,常见的类型有 HTML、CSS、JS、图片、视频、JSON
- HTML、CSS、JS在传输时都是通过放在响应报文中的响应体作传输,返回给浏览器
HTTP 服务前置知识点 IP
IP分类:
IP/IP地址,本身是一个32bit的数字标识,按8bit一组,加
.拆分,并转10进制- 如 192.168.1.3,等价于 11000000 10101000 00000001 00000011
IP作用:标识网络中的设备,实现设备间通信
- 局限:2进制32bit的数字,最多能标记42 9496 7296个设备
- 临时解决办法:共享IP,包括区域共享、家庭共享
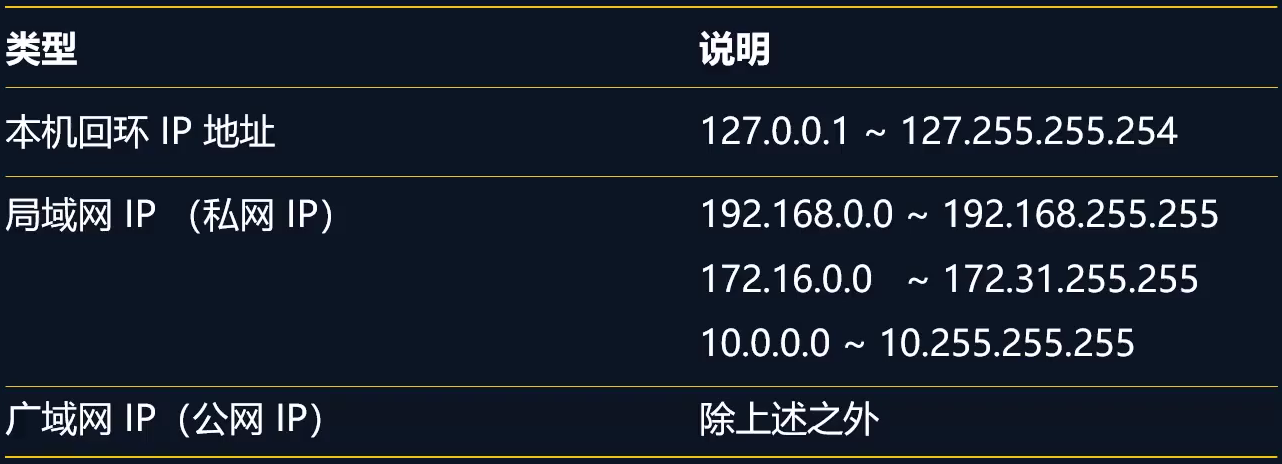
局域网IP,即私网IP,局域网/私网内的设备,共享一个出口IP
广域网IP,即公网IP,一个局域网/私网共用一个广域网IP
共享IP,本质上是指公网IP共享
- 有可能运营商外面还会再套一层IP地址
- 运营商给的如果不是公网IP,那么进入猫/路由器的还是一个区域共享IP
局域网IP可被多个子网复用,减少了IP的占用
局域网IP段包括:
- 192.168.0.0 到 192.168.255.255
- 172.16.0.0 到 172.31.255.255
- 10.0.0.0 到 10.255.255.255
家庭/公司间通信,通过公网IP,实现子网与外界通信
- 广域网/公网IP,就是除局域网IP段,以及除本机回环IP地址段,以外的IP地址
本机回环IP地址
- 127.0.0.1为本地回环IP地址,此IP地址永远指向本地本机,即localhost
- 本地回环IP地址段,包括从127.0.0.1到127.255.255.254及其之间的地址,都是指向本机
知乎介绍IP 地址标准分类
HTTP 服务
HTTP 服务前置知识点 端口
端口号定义:
- 定义:端口号是应用程序的数字标识
- 可以理解为服务进程所对外使用的接口号
- 一台现代计算机有65536个端口(端口号从 0 到 65535)
- 一个应用程序可以使用一个或多个端口
- 定义:端口号是应用程序的数字标识
端口号的主要作用:
- 实现 不同主机 应用程序 之间的通信
- 通信时加上端口,让对应端口号的程序去处理报文
重点端口号:
- HTTP 协议默认端口是 80 ,没写端口号的情况/默认端口号,就是用的80端口
- HTTPS 协议的默认端口是 443
- HTTP 服务开发常用端口有 3000,8080,8090,9000 等
创建及测试 HTTP 服务
使用 nodejs 创建 HTTP 服务步骤
- 是nodejs中的http模块,与协议名称一致
http 模块/对象中的.createServer方法
- 箭头函数两个参数,两个形参,名字自定
- 形参1,request 意为请求. 实参调用时,是对请求报文的封装对象, 通过 request 对象,可以获得请求报文的数据,如请求头、请求行、请求体等
- 形参2,response 意为响应. 实参调用时,是对响应报文的封装对象, 通过 response 对象,可以设置响应报文,如响应头、响应行、响应体等
- 在接收http请求时,触发该.createServer方法
//1. 导入 http 模块/对象
const http = require('http');
//2. 创建服务对象 create 创建 server 服务,http 模块/对象中的.createServer方法
// request 意为请求. 是对请求报文的封装对象, 通过 request 对象可以获得请求报文的数据
// response 意为响应. 是对响应报文的封装对象, 通过 response 对象可以设置响应报文
const server = http.createServer((request, response) => {
// response.end('Hello HTTP'); //设置响应体,并.end方法结束响应
response.setHeader('content-type', 'text/html;charset=utf-8');
response.end('你好'); //设置响应体,并.end方法结束响应
});
//3. 监听端口, 启动服务
server.listen(9000, () => {
console.log('服务已经启动....')
});http.createServer 里的回调函数的执行时机:
当接收到 HTTP 请求的时候,就会执行启动 HTTP 服务
命令行运行 node 文件名.js
浏览器请求对应端口测试 HTTP 服务
http://127.0.0.1:9000
HTTP 服务五个注意事项:
命令行
ctrl + c停止服务- 需要注意,是在运行服务的命令行中执行
ctrl + c来停止服务
- 需要注意,是在运行服务的命令行中执行
当服务启动后,更新代码
必须重启服务才能生效响应体/响应内容中有中文会产生乱码,通过设置响应头字符集来解决中文乱码
// 通过设置响应头字符集来解决乱码
// response.setHeader设置响应头(第一个参数content-type响应头参数名字,响应头的参数的值)
response.setHeader('content-type', 'text/html;charset=utf-8');
// 本质上,是在响应回来时,多加一个响应头设置,content-type:text/html;charset=utf-8- 端口号被占用的情况
# 当端口被占用时,在终端中会有如下显示
Error: listen EADDRINUSE: address already in use :::9000端口号被占用的应对办法:
- 关闭当前正在运行监听端口的服务 (
使用较多) - 修改为其他端口号
- 重点端口号:
- HTTP 协议默认端口是 80
- 没写端口号的情况/默认端口号,就是用的80端口,
- 使用简单,服务端占用的端口为默认的80端口时,访问时在域名/ip后面不需要额外加端口
- HTTPS 协议的默认端口是 443
- HTTP 服务开发常用端口有 3000,8080,8090,9000 等
- HTTP 协议默认端口是 80
如果端口被其他程序占用,可以使用
资源监视器找到占用端口的程序的pid,然后使用任务管理器,通过pid锁定占用的程序,关闭对应的程序 Linux下,通过 查看进程命令netstat -tulnp,找出进程的端口占用情况,以及进程的pid标识号;再通过 杀进程命令kill 加进程的pid标识号,杀掉对应进程
浏览器查看 HTTP 报文
- 先跑起HTTP服务,然后通过浏览器查看HTTP 报文
- 浏览器,右键检查/F12 > 网络标签页,会显示页面使用/加载过程中的 所有请求 和 响应内容
- 浏览器,可通过按
F5或ctrl + r刷新 - Google/edge浏览器的默认请求行为:每次打开页签,都会请求网址获取页签的icon
查看的操作步骤
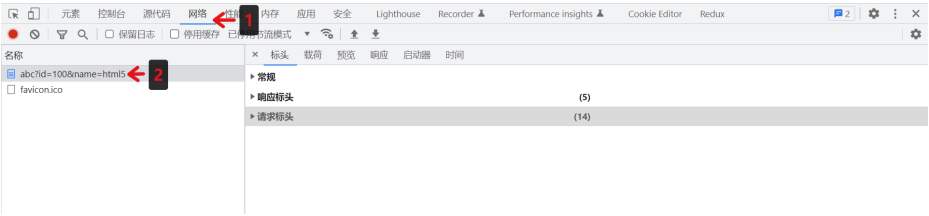
查看请求行与请求头
(在请求头查看中,点击 查看源代码/解析结果 ,以查看请求行)
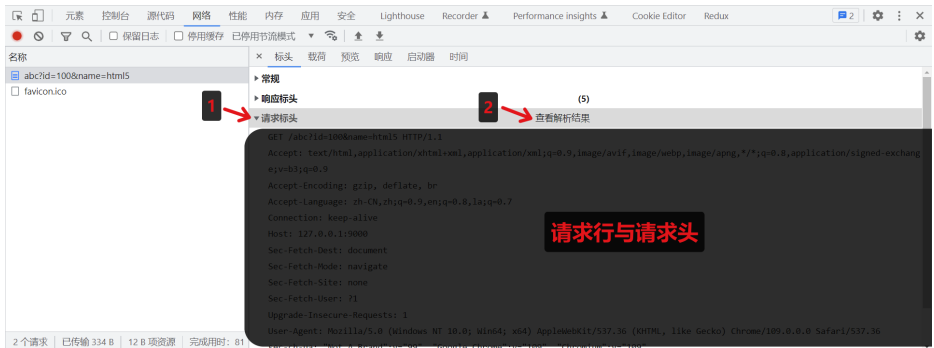
查看请求体
(查看请求体,需要模拟post请求,通常大多数情况下get请求的请求体是空的)
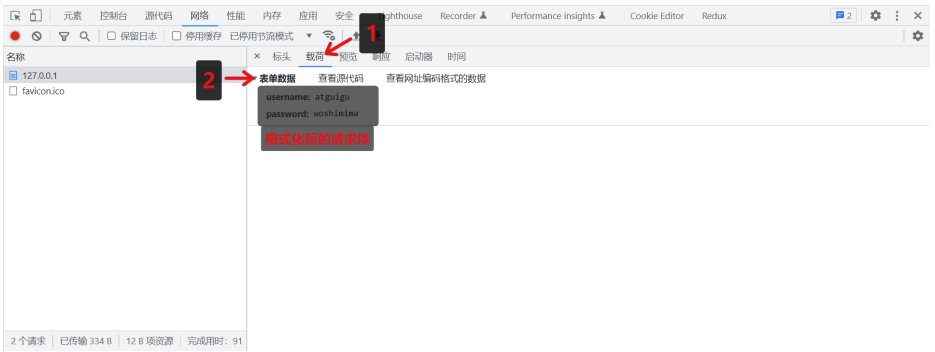
查看 URL 查询字符串内容
(载荷中会将查询字符串内容作格式化处理,以键名:键值对形式展示)
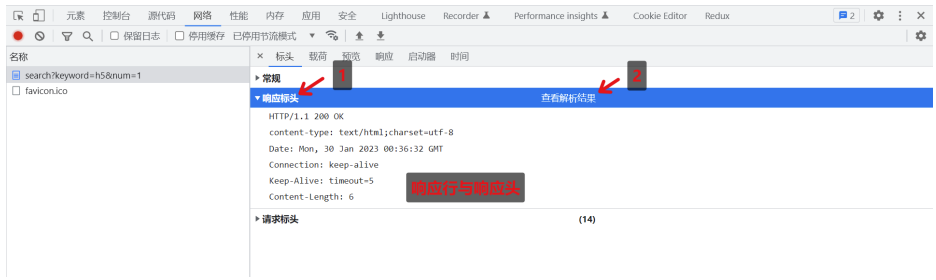
查看响应行与响应头
(在响应头查看中,点击 查看源代码/解析结果 ,以查看响应行)
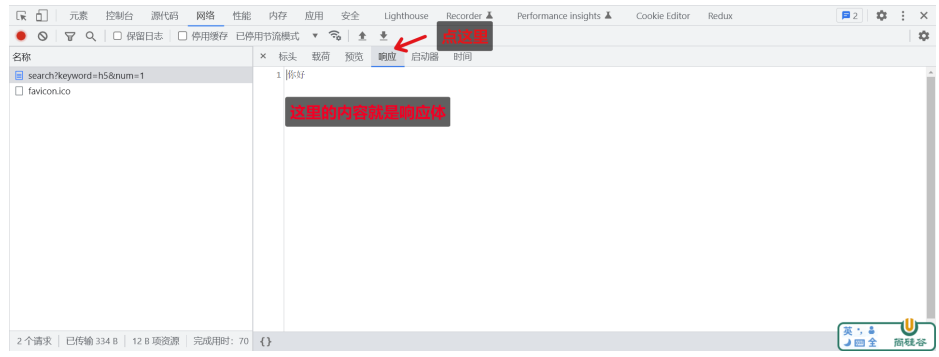
查看响应体
(点击 响应标签页 ,以查看响应体内容)
获取 HTTP 请求报文
在 HTTP 服务中,需要通过
request对象,获取请求的数据- 目的:提取需要的数据,以便按需要返回数据
获取 HTTP 请求报文 实际作业流程:
- 浏览器调试中,可以看到请求报文
- 浏览器输入地址,回车后,会将浏览器端的请求报文,提交到对应服务器端的对应端口
- 服务器端的
http模块.js上的服务对象回调函数,接收请求报文,并返回响应报文 - 在服务器端,如需获取请求报文的内容,需要将获取请求报文的业务逻辑,放在所创建的服务对象的回调函数中
- 当服务器端通过
node http模块.js命令跑起来后,再通过浏览器访问,就能在终端中,看到http服务回调函数的结果
| 含义 | 语法 | 重点掌握 |
|---|---|---|
| 请求方法 | request.method | * |
| 请求版本 | request.httpVersion | |
| 请求路径 | request.url | * |
| URL 路径 | require('url').parse(request.url).pathname | * |
| URL 查询字符串 | require('url').parse(request.url, true).query | * |
| 请求头 | request.headers | * |
| 请求体 | request.on('data', function(chunk){})request.on('end', function(){}); |
注意事项:
- request.url 只能获取路径以及查询字符串,无法获取 URL 中的域名以及协议或端口的内容
- request.headers 将请求信息转化成一个对象,并将属性名都转化成了『小写』,包含了请求头的所有内容
- 另注:双拼词由于属性名中带有
-符号,并非标准的标识符,因此双拼词都带了'引号,以便通过解析作为键名
- 另注:双拼词由于属性名中带有
- 关于路径:如果访问网站的时候,只填写了 IP 地址或者是域名信息,此时请求的路径为『
/』 - 关于 favicon.ico:这个请求是属于浏览器自动发送的请求
//1. 导入 http 模块
const http = require('http');
//2. 创建服务对象,获取请求报文内容
const server = http.createServer((request, response) => {
//获取请求的方法
console.log(request.method);
//获取请求的 url
console.log(request.url);// 只包含 url 中的路径与查询字符串,不包括url的协议、域名、或端口
//获取 HTTP 协议的版本号
console.log(request.httpVersion);
//获取 HTTP 的请求头
console.log(request.headers); // 将请求信息转化成一个对象,并将属性名都转化成了『小写』
console.log(request.headers.host); // 获取其中某个请求头信息值
response.end('http'); //设置响应体
});
//3. 监听端口, 启动服务
server.listen(9000, () => {
console.log('服务已经启动....')
});提取HTTP报文的请求体步骤:
- 声明一个变量,用于接收响应体的结果
- 给request绑定data事件,传入回调函数
- request本身是可读流对象,通过chunk,一点点取出请求体内容
body += chunkchunk每次取出一部分,并存入到body当中- chunk本身是一个buffer,如果作加法运算,内部会将其自动转换成字符串(在对buffer进行加法运算时, 会自动调用 toString 方法;可写成
body += chunk.toString())
- 绑定 end 事件,作为可读流完成读取后的触发事件
通过带post的html页面逻辑,将post请求提交到服务端上的http模块.js,然后提取HTTP报文的请求体
//1. 导入 http 模块
const http = require('http');
//2. 创建服务对象
const server = http.createServer((request, response) => {
//1. 声明一个变量
let body = '';
//2. 绑定 data 事件
request.on('data', chunk => {
// 了解即可,后面会有更好的方法
body += chunk; // 在对buffer进行加法运算时, 会自动调用 toString 方法
})
//3. 绑定 end 事件
request.on('end', () => {
console.log(body);
// 添加浏览器响应
response.end('Hello HTTP');
});
});
//3. 监听端口, 启动服务
server.listen(9000, () => {
console.log('服务已经启动....')
});提取HTTP报文中URL的路径与查询字符串
- 意义:服务器通过URL的路径与查询字符串,来返回相应参数内容的结果
步骤:
- 导入 url 模块
const url = require('url');url 模块是js中的内置模块,专门用于解析url - 创建服务对象
const server = http.createServer((request, response) => {箭头函数} - request.url属性中已经包含了路径和查询字符串
- 箭头函数中,使用url对象中的parse方法
url.parse(request.url, true)来解析 request.url - 通过往parse方法,配置传入第二个参数为true,query属性将会被设置为一个对象(可通过打印确认)
- 如不传第二个参数为true,默认的打印的结果是:字符串形式的查询字符串
?keyword=xxxxx - 鼠标悬停于parse方法上,能看到方法的使用介绍
- 如不传第二个参数为true,默认的打印的结果是:字符串形式的查询字符串
- 导入 url 模块

function parse(urlString: string): url.UrlWithStringQuery (+3 overloads)
The url.parse() method takes a URL string, parses it, and returns a URL object.
A TypeError is thrown if urlString is not a string.
A URIError is thrown if the auth property is present but cannot be decoded.
url.parse() uses a lenient, non-standard algorithm for parsing URL strings. It is prone to security issues such as host name spoofing and incorrect handling of usernames and passwords. Do not use with untrusted input. CVEs are not issued for url.parse() vulnerabilities. Use the WHATWG URL API instead.
@since — v0.1.25
@deprecated — Use the WHATWG URL API instead.
@param urlString — The URL string to parse.
@param parseQueryString
If true, the query property will always be set to an object returned by the querystring module's parse() method. If false, the query property on the returned URL object will be an unparsed, undecoded string.
@param slashesDenoteHost
If true, the first token after the literal string // and preceding the next / will be interpreted as the host. For instance, given //foo/bar, the result would be {host: 'foo', pathname: '/bar'} rather than {pathname: '//foo/bar'}.
========================================
function parse(urlString: string): url.UrlWithStringQuery (+3 个重载)
url.parse() 方法获取 URL 字符串,解析它,并返回一个 URL 对象。
如果 urlString 不是字符串,则会引发 TypeError。
如果 auth 属性存在但无法解码,则会引发 URIError。
url.parse() 使用一种宽松的非标准算法来解析 URL 字符串。它容易出现安全问题,例如主机名欺骗以及用户名和密码处理不正确。不要与不受信任的输入一起使用。CVE 不会针对 url.parse() 漏洞发布。请改用 WHATWG URL API。
@since — v0.1.25
@deprecated – 请改用 WHATWG URL API。
@param urlString — 要解析的 URL 字符串。
@param parseQueryString
如果为 true,则 query 属性将始终设置为 querystring 模块的 parse() 方法返回的对象。如果为 false,则返回的 URL 对象上的 query 属性将是未解析、未解码的字符串。
@param slashesDepresentHost
如果为 true,则文本字符串 // 之后和下一个 / 之前的第一个标记将被解释为 host。例如,给定 //foo/bar,结果将是 {host: 'foo', pathname: '/bar'},而不是 {pathname: '//foo/bar'}。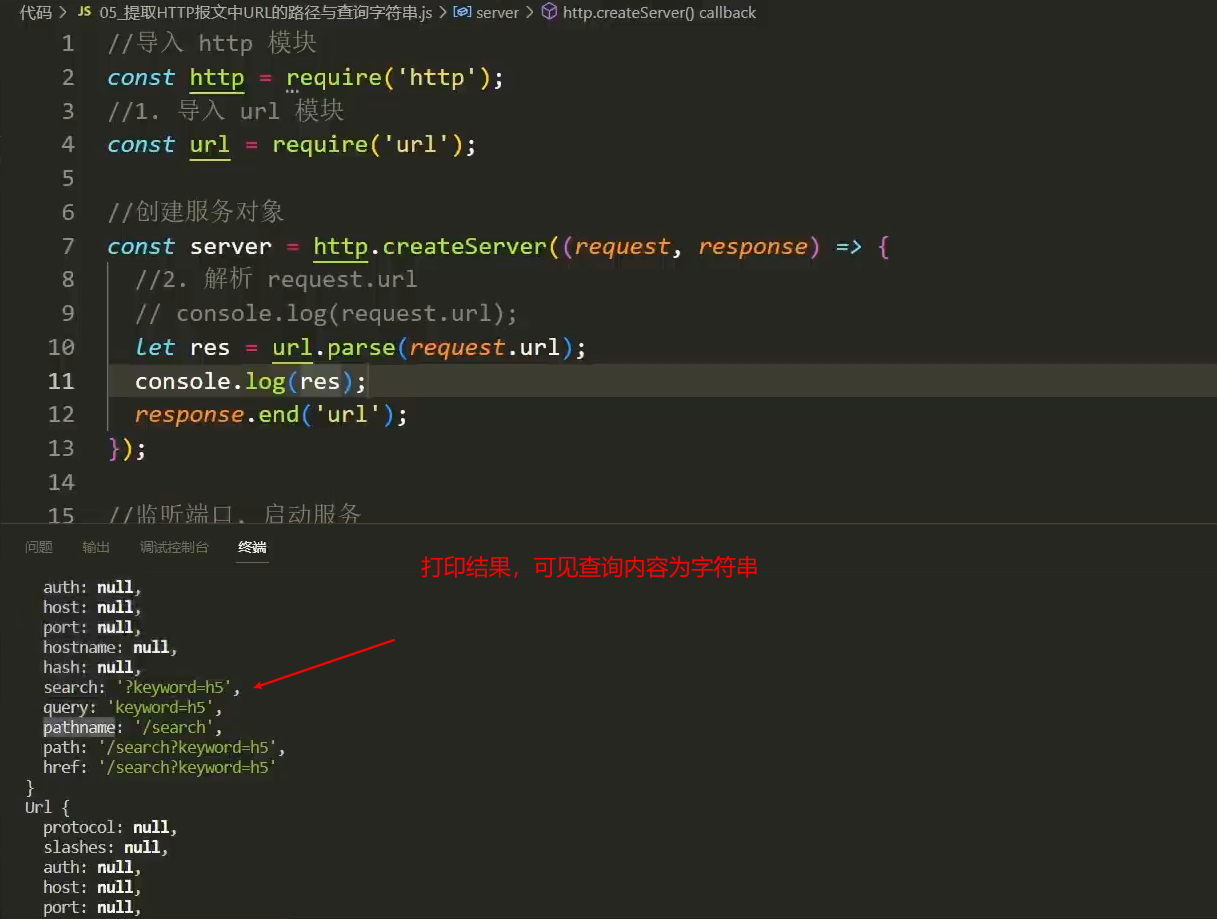
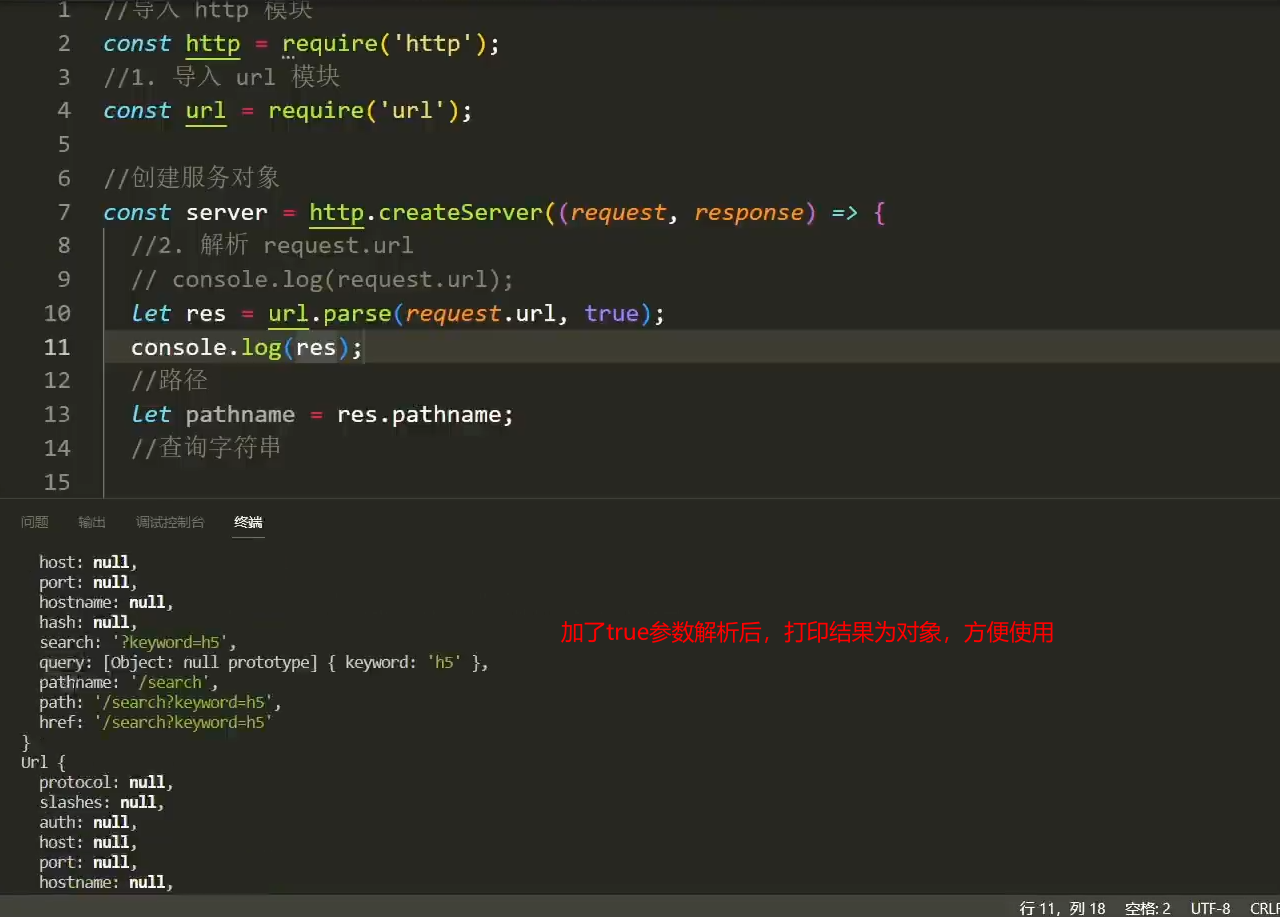
//导入 http 模块
const http = require('http');
//1. 导入 url 模块
const url = require('url');
// 创建服务对象
const server = http.createServer((request, response) => {
//2. 解析 request.url
// console.log(request.url);
let res = url.parse(request.url, true);
// 接收解析的路径结果
let pathname = res.pathname;
// 接收解析的查询字符串
let keyword = res.query.keyword;
response.end('url');
});
//监听端口, 启动服务
server.listen(9000, () => {
console.log('服务已经启动....')
});提取HTTP报文中URL的路径与查询字符串 - 方法2
- 原理:通过实例化创建对象,再通过对象的属性,提取url中的内容
步骤及注意点:
- 不需要导入 url 模块
- 创建服务对象,并在回调中,实例化 URL 的对象
let url = new URL(传参) - 传参时,传入完整的路径作为唯一参数,打印可得知,实例化的url是一个对象
- 不能单独传路径和查询字符串,不传协议和域名和端口,可改为分作两个参数传入,两个参数能补全为标准的url格式,使得合法即可
- 后续通过
对象.属性.get方法(取出键名),通过url.searchParams这个对象属性,通过get方法取出键名下的键值
最新的 nodejs 23.5.0 中解析绝对或相对的输入网址的方法 https://nodejs.cn/api/url.html#new-urlinput-base
//导入 http 模块
const http = require('http');
// 创建服务对象
const server = http.createServer((request, response) => {
// 实例化 URL 的对象
// let url = new URL(传参)
// 传入一个参数时,如:
// let url = new URL('https://www.xxxx.com/search?a=100&b=200'); // 传入完整的路径作为唯一参数传入
// console.log(url); // 打印可得知,url是一个对象
// 不能单独传路径和查询字符串,不传协议和域名和端口,可改为分作两个参数传入,两个参数能补全为标准的url格式,使得合法即可
// let url = new URL('/search?a=100&b=200', 'http://127.0.0.1:9000');
let url = new URL(request.url, 'http://127.0.0.1');
//输出路径
console.log(url.pathname);
//输出 keyword 查询字符串,通过url.searchParams这个对象属性,通过get方法取出键名下的键值
console.log(url.searchParams.get('keyword'));
response.end('url new');
});
//监听端口, 启动服务
server.listen(9000, () => {
console.log('服务已经启动....')
});练习:
- 按照以下要求/接口文档协议,搭建 HTTP 服务
| 请求类型(方法) | 请求地址 | 响应体结果 |
|---|---|---|
| get | /login | 登录页面 |
| get | /reg | 注册页面 |
分析:
- 只要有请求,参数会被传入创建的服务对象的箭头函数中
- 根据传入的参数,判断请求的方法,以及判断请求的url路径,是否与要求/接口文档协议一致
- 可通过解构赋值的方法简写,如将
let method = request.method;简写为let { method } = request; - 不符合请求头路径判断时,会出现没有结果返回,链接也不断开,占用双方资源
- 因此,在获取请求头响应的判断中,需要加入“当请求头路径都不满足条件时”的操作:直接调.end方法+提示,以断开链接
- 如浏览器默认的第二个页签icon请求(路径是
/favicon.ico),由于不符合获取请求头响应的判断(pathname ===),因此不执行对应符合请求头路径判断的.end方法
- 如浏览器默认的第二个页签icon请求(路径是
//1. 导入 http 模块
const http = require('http');
//2. 创建服务对象
const server = http.createServer((request, response) => {
// 获取请求的方法,解构赋值简写,因为request中有method属性
let { method } = request;
// 获取请求的 url 路径
let { pathname } = new URL(request.url, 'http://127.0.0.1');
// 打印确认
console.log(method)
console.log(pathname)
// 获取请求头响应的判断
response.setHeader('content-type', 'text/html;charset=utf-8');
// 判断
// 实际上的写法,参见express框架中的路由,app.post('/login', (req, res) => {}
if (method === 'GET' && pathname === '/login') {
// 登录的情形
response.end('登录页面');
} else if (method === 'GET' && pathname === '/reg') { // register 注册
response.end('注册页面');
} else {
// 不满足时,断开连接,响应状态码还是200
response.end('Not Found');
}
});
//3. 监听端口 启动服务
server.listen(9000, () => {
console.log('服务已经启动.. 端口 9000 监听中....');
});//1、引入http模块
const http = require("http");
//2、建立服务
const server = http.createServer((request, response) => {
let { url, method } = request; //对象的解构赋值
//设置响应头信息
//解决中文乱码
response.setHeader("Content-Type", "text/html;charset=utf-8");
if (url == "/register" && method == "GET") {
response.end("注册页面");
} else if (url == "/login" && method == "GET") {
response.end("登录页面");
} else {
response.end("<h1>404 Not Found</h1>");
}
});
//3、监听端口
server.listen(8000, () => {
console.log('服务启动中....');
});设置 HTTP 响应报文
在js/nodejs中,设置 HTTP 响应报文/响应结果,建立API
| 作用 | 语法 |
|---|---|
| 设置响应状态码 | response.statusCode |
| 设置响应状态描述 | response.statusMessage ( 直接赋值,用的非常少 ) |
| 设置响应头信息 | response.setHeader('头名', '头值') |
| 设置响应体 | response.write('xx') response.end('xxx') |
| 类别 | 默认不设置的情况下的返回值 |
|---|---|
| 响应状态码 | 返回 200 |
| 响应状态描述 | 绝大多数情况下与响应状态码自动对应 |
注意:
- 响应状态码的返回,后面的可以覆盖前面的
- 响应体的设置,write方法 和 end方法 结合使用时,响应的write内容会和end内容结合后再返回浏览器,响应体相对分散
- 每一个请求/每一次执行回调箭头函数时,在处理的时候,必须要且只有1个 end 方法执行,回调函数中不能有两个end方法
- 单独使用 end 方法 响应体相对集中
- 一般使用write方法设置了响应体时,在end方法中就不再设置响应体内容
- write方法设置响应体是支持多次调用返回响应体的
- end方法,可以传入字符串、也可以传入buffer类型
设置 HTTP 响应报文/响应结果
//导入 http 模块
const http = require('http');
//创建服务对象
const server = http.createServer((request, response) => {
//1. 设置响应状态码
// response.statusCode = 203;
// response.statusCode = 404; // 可覆盖前次的返回
//2. 响应状态的描述
// response.statusMessage = 'iloveyou';
//3. 响应头
// response.setHeader('content-type', 'text/html;charset=utf-8');
// response.setHeader('Server', 'Node.js'); // 如 Server 字段,自定义标识服务端名字
// response.setHeader('myHeader', 'test test test'); // 自定义响应头
// response.setHeader('test', ['a','b','c']); // 设置多个自定义同名响应头
//4. 响应体的设置;write 和 end 的两种使用情况
// write方法 和 end方法 的结合使用 响应的write内容会和end内容结合后再返回浏览器,响应体相对分散,
response.write('love');
response.write('love');
response.write('love');
response.write('love');
response.end('love'); //设置响应体,//每一个请求/每一次执行回调箭头函数时,在处理的时候,必须要且只有1个 end 方法执行
response.end('xxx'); //设置响应体,单独使用 end 方法 响应体相对集中
});
//监听端口, 启动服务
server.listen(9000, () => {
console.log('服务已经启动....')
});练习搭建 HTTP 响应服务
- 搭建 HTTP 服务,响应一个 4 行 3 列的表格,并且要求表格有
隔行换色效果,且点击单元格能高亮显示
要点:
- 响应的内容,在引入时,通过反引号引入,可以多行换行
- 响应的内容,在引入时,应尽量为标准的html结构,并可以将其单独抽离成独立文件
- 在http服务对象中,借助同步的api方法fs.readFileSync,读取文件内容,引入抽离后的文件作返回response.end(文件)
- 抽离后,再对抽离后的文件作修改(修改html文件内容),不需重新启动服务,发现http服务已更新;因为每次发请求,HTTP服务对象都会再次去读取抽离后的文件,逻辑链没有变化
//导入 http 模块
const http = require('http');
//创建服务对象
const server = http.createServer((request, response) => {
// 换成反引号引入,可以换行;通过并且将独立的表格标签,换为标准的html结构
response.end(`
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
td{
padding: 20px 40px;
}
table tr:nth-child(odd){
background: #aef;
}
table tr:nth-child(even){
background: #fcb;
}
table, td{
border-collapse: collapse;
}
</style>
</head>
<body>
<table border="1">
<tr><td></td><td></td><td></td></tr>
<tr><td></td><td></td><td></td></tr>
<tr><td></td><td></td><td></td></tr>
<tr><td></td><td></td><td></td></tr>
</table>
<script>
//获取所有的 td
let tds = document.querySelectorAll('td');
//遍历
tds.forEach(item => {
// 监听/绑定事件
item.onclick = function(){
this.style.background = '#222';
}
})
</script>
</body>
</html>
`); //设置响应体
});
//监听端口, 启动服务
server.listen(9000, () => {
console.log('服务已经启动....')
});//导入 http 模块
const http = require('http');
const fs = require('fs');
//创建服务对象
const server = http.createServer((request, response) => {
//借助同步的api方法fs.readFileSync,读取文件内容,引入抽离后的 /10_table.html
let html = fs.readFileSync(__dirname + '/10_table.html');
response.end(html); //设置响应体
});
//监听端口, 启动服务
server.listen(9000, () => {
console.log('服务已经启动....')
});网页资源的基本加载过程
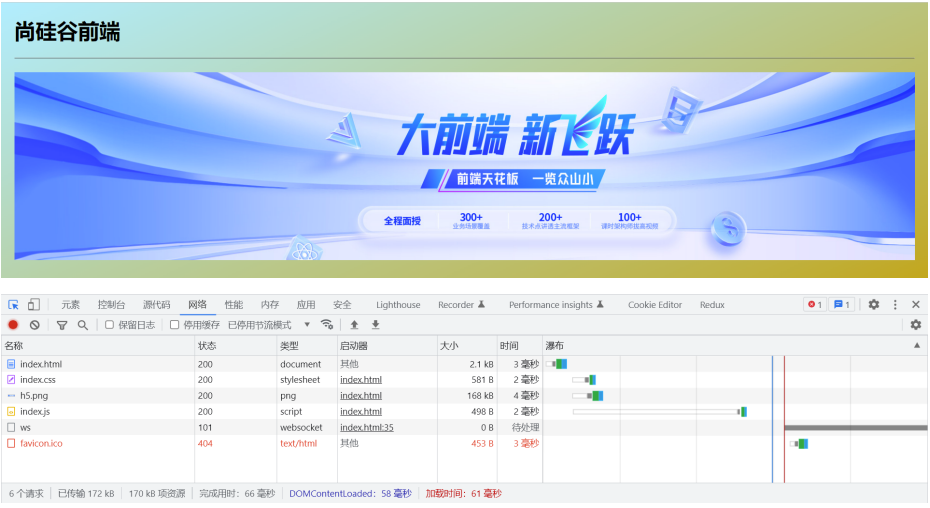
网页资源的加载都是循序渐进的
理解了这个内容对于后续的学习与成长有非常大的帮助- 首先获取 HTML 的内容
- 然后解析 HTML 在发送其他资源的请求,如 CSS,Javascript,图片等
因此,上图网页的加载,经过了多次资源的请求
- ws(websocket)请求是vscode插件让网页实现自动刷新的请求
- icon获取浏览器标签页图标的请求,是浏览器自发请求行为
- 涉及页面内容的请求,包括:html页面请求、css样式请求、图片资源请求、js逻辑请求
- 可通过时间流确认先后
- 最先发的是html响应头请求,获取响应体页面html内容,浏览器对响应体解析
- 根据html页面解析顺序,解析分拆到外部要引入的css样式,因此再次向该域名+端口,发送请求获取css内容,通过响应体返回css,浏览器加载解析返回的css样式
- 根据html页面解析顺序,解析分拆到外部要引入的图片资源,对于图片类资源,在浏览器页面检查调试中,可在网络>预览下,查看返回的响应体资源
- 根据html页面解析顺序,解析分拆到外部要引入的js
- 多个页面资源的请求,都是并行发送出去,没有队列性,不会单独等某个资源完成返回后再发另一个请求
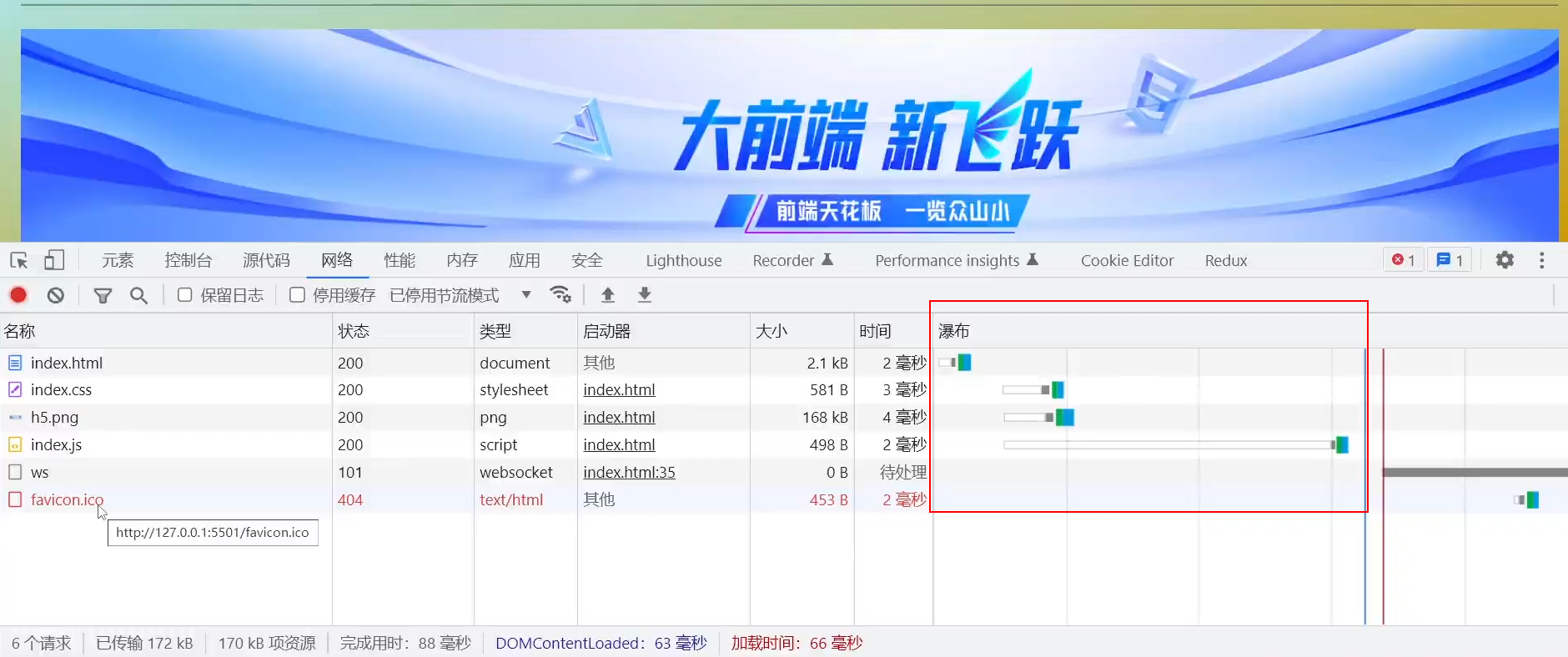
扩展 HTTP 响应服务 实现外部资源引入
将分拆到外部的html、css、js的资源,引入回到页面
- 在将页面的资源分拆成独立文件后,在前端的html页面中,通过标签对属性,实现对css、js、图片资源等的引入
- 在后端的执行HTTP服务的node.js文件中,接收的请求,传入到箭头回调函数中
- 因此,需要在回调函数中,根据前端页面请求的类型,返回相应的服务资源
- 获取请求url的路径,根据pathname来区分,确认请求的资源
- 默认路径下的请求/第一次请求,返回基础的html资源,让浏览器加载
- 判断后续的请求,根据pathname,返回对应的资源响应
- 如果请求都不符合pathname条件,则返回状态码,如
response.statusCode = 404 - 注意分拆后的文件,不要有除该类型以外的代码
//导入 http 模块
const http = require('http');
const fs = require('fs');
//创建服务对象
const server = http.createServer((request, response) => {
//获取请求url的路径
let { pathname } = new URL(request.url, 'http://127.0.0.1');
// 默认路径下的请求/第一次请求,返回基础的html资源,让浏览器加载
// 实际上的写法,参见express框架中的路由,app.post('/login', (req, res) => {}
if (pathname === '/') {
// 读取文件内容
let html = fs.readFileSync(__dirname + '/10_table.html');
response.end(html); //设置响应体
} else if (pathname === '/index.css') {
// 读取文件内容
let css = fs.readFileSync(__dirname + '/index.css');
response.end(css); //设置响应体
} else if (pathname === '/index.js') {
// 读取文件内容
let js = fs.readFileSync(__dirname + '/index.js');
response.end(js); //设置响应体
} else {
response.statusCode = 404;
response.end('<h1>404 Not Found</h1>');
}
});
//监听端口, 启动服务
server.listen(9000, () => {
console.log('服务已经启动....')
});资源状态区别
静态资源是指
内容长时间不发生改变的资源- 例如图片,视频,CSS 文件,JS文件,HTML文件,字体文件等
- 内容长时间不发生改变,是指在项目运行过程中的状态,生产环境上线后,用户访问时,此类静态资源一般不变动
动态资源是指
内容经常更新的资源- 例如百度首页,网易首页,京东搜索列表页面等
搭建静态资源服务
服务器上的静态资源服务,当客户端访问时,给客户端浏览器响应返回资源
- 通过在服务器上搭建静态资源服务,取代前两节中在创建的HTTP响应服务对象中逐一返回的方式
需求:
- 创建一个 HTTP 服务,端口为 9000,满足如下需求
| 浏览器请求方式 | 请求地址路径 | 请求方法 | 响应的资源路径 |
|---|---|---|---|
| GET | /index.html | 响应 | page/index.html 的文件内容 |
| GET | /css/app.css | 响应 | page/css/app.css 的文件内容 |
| GET | /images/logo.png | 响应 | page/images/logo.png 的文件内容 |
- 解决:
- 观察可知,最终访问时的文件路径,是在浏览器发起请求的地址路径前,拼接文件的绝对路径
__dirname,以及目录路径
- 观察可知,最终访问时的文件路径,是在浏览器发起请求的地址路径前,拼接文件的绝对路径
/**
* 需求:
* 创建一个 HTTP 服务,端口为 9000,满足如下需求
* GET /index.html 响应 page/index.html 的文件内容
* GET /css/app.css 响应 page/css/app.css 的文件内容
* GET /images/logo.png 响应 page/images/logo.png 的文件内容
*/
//导入 http 模块
const http = require('http');
const fs = require('fs');
// 创建服务对象
const server = http.createServer((request, response) => {
// 获取请求url的路径
let { pathname } = new URL(request.url, 'http://127.0.0.1');
// 声明一个变量,定义为 “文件的绝对路径__dirname拼接'/page'文件夹路径”
// 这个变量,就是网站的根目录
let root = __dirname + '/page';
// 通过更改资源文件夹的路径,来变更网站的根目录
// let root = __dirname + '/../';
// 拼接文件路径,在网站的根目录基础上,再拼接上请求地址
let filePath = root + pathname;
//读取文件 fs 异步 API(还没学同步的错误处理)
fs.readFile(filePath, (err, data) => {
if (err) {
console.log(err);
//设置字符集
response.setHeader('content-type', 'text/html;charset=utf-8');
//如果出错,判断错误的代号,并相应返回对应的状态码和描述
response.statusCode = 500;
response.end('文件读取失败');
return;
}
//响应文件内容
response.end(data);
})
});
//监听端口, 启动服务
server.listen(9000, () => {
console.log('服务已经启动....')
});网站根目录或静态资源目录
- HTTP 服务,在应对请求时,到哪个文件夹中寻找静态资源,那个文件夹就是
静态资源目录,也称之为网站根目录- 网站根目录/静态资源目录,本质上定义相同,仅是叫法差异
文件的绝对路径__dirname 拼接 '/page'文件夹路径就是网站的根目录- 通过更改资源文件夹的路径,来变更网站的根目录
思考:vscode 中使用 live-server 访问 HTML 时, 它启动的服务中网站根目录是谁?
- 就是vscode终端所打开的文件夹目录,作为网站根目录所启动的服务
- 其他webstorm等ide编译器也同理,均为打开的文件夹目录,作为live-server的网站根目录
// 获取请求url的路径
let { pathname } = new URL(request.url, 'http://127.0.0.1');
// 声明一个变量,定义为 “文件的绝对路径__dirname拼接'/page'文件夹路径”
// 这个变量,就是网站的根目录
let root = __dirname + '/page';
// 通过更改资源文件夹的路径,来变更网站的根目录
// let root = __dirname + '/../';
// 拼接文件路径,在网站的根目录基础上,再拼接上请求地址
let filePath = root + pathname;网页中的 URL
背景:
- 理解路径 是 理解前/后端的交互 的前提 (前浏览器端/后服务端)
网页中的 URL 主要分为两大类:
- 相对路径与绝对路径
绝对路径可靠性强,而且相对容易理解,在项目中运用较多
- 平时访问网站时,如网站的地址不显示协议,则一般为默认的http协议,可通过复制地址栏到浏览器新页签上查看确认
- 通过默认的http协议访问网站时,往网站发起的第一个请求是http,此协议不安全,容易被假冒、被冲
- 此时,通常正规网站(装了证书后的网站)作为服务端,会将接收到的第一个http请求,给浏览器返回一个301的重定向,让浏览器重定向到带https协议的地址
- 通过浏览器调试查看,可以确认,大部分网站的资源加载路径,都是采用的:/在前,省略
协议+域名+端口,只保留文件绝对路径的形式,不受主机名(域名或IP)更换的影响

| 绝对路径形式 | 特点:路径前面必有反斜线 / 东北<--->西南 |
|---|---|
完整体包含所有部分即 协议、域名、路径、端口:http://atguigu.com/web | 直接向目标资源发送请求,相对简单,容易理解。 网站的外链会用到此形式(多用于链接到外部网站,如页脚友链) |
省略协议://atguigu.com/web | 在与当前所在页面 URL 的协议拼接形成完整 URL 后再发送请求。 大型网站用的比较多,平时使用较少,了解即可 |
省略协议+域名+端口只保留路径: /web | 与当前所在页面 URL 的协议、主机名、端口拼接形成完整 URL 再发送请求。 中小型网站,使用频率较高,不受主机名(域名或IP)更换的影响 |
- 相对路径在发送请求时,需要与
当前页面 URL 路径进行计算,得到完整 URL 后,再发送请求,- 由于相对路径是与当前页面url相关,不可靠,因此学习阶段用的较多,正式项目使用少
- 例如当前网页 url 为 http://www.atguigu.com/course/h5.html
| 相对路径形式 | 计算后最终的 URL |
|---|---|
| ./css/app.css | http://www.atguigu.com/course/css/app.css |
| js/app.js | http://www.atguigu.com/course/js/app.js |
| ../img/logo.png | http://www.atguigu.com/img/logo.png |
| ../../mp4/show.mp4 | http://www.atguigu.com/mp4/show.mp4 |
./:为当前层级./加目录路径:为当前文件所在的文件夹目录下,加目录路径- 直接是
目录路径:为当前文件所在的文件夹目录下,加目录路径 ../加目录路径:为回到上一级目录的路径下,再加目录路径../最多退到网站根目录/最外层- 目录操作,与Linux下的cd操作一致
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>URL</title>
</head>
<body>
<!-- 绝对路径 -->
<a href="https://www.baidu.com">百度</a>
<a href="//jd.com">京东</a>
<a href="/search">搜索</a>
<hr>
<!-- 相对路径 -->
<a href="./css/app.css">访问CSS</a>
<a href="js/app.js">访问JS</a>
<a href="../img/logo.png">访问图片</a>
<a href="../../img/logo.png">访问图片</a>
</body>
</html>网页中使用 URL 的场景小结
路径的使用,包括但不限于如下场景:
- a 标签 href ----页面中的跳转链接
- link 标签 href ----html页面中引入外部css
- script 标签 src ----属性
- img 标签 src ----属性
- video audio 标签 src ----属性
- form 中的 action
- AJAX 请求中的 URL
请求流
- 前浏览器端页面写路径,请求传递给后服务器端服务对象箭头函数接收
- 服务器端根据创建的nodejs的http服务,去解析请求,解析传入路径的资源,返回响应报文给前浏览器端
页面资源的引入,采用省略
协议+域名+端口的绝对路径- 在页面发送请求时,会自适应地拼接当前页面的协议、主机名、端口,形成完整url后请求
<!-- 页面资源的引入 不采用./开头,相对路径不可靠 -->
<link rel="stylesheet" href="./css/app.css">
<!-- 页面资源的引入,采用第二种绝对路径,在页面发送请求时,自适应拼接当前页面的协议、主机名、端口,形成完整url后请求 -->
<link rel="stylesheet" href="/css/app.css">
<!-- 页面资源的引入 不采用完整体绝对路径,太详细,不方便改 -->
<link rel="stylesheet" href="http://127.0.0.1:9000/css/app.css">设置响应资源的 MIME 类型
背景:完善此前搭建的静态资源服务,设置响应资源的 MIME 类型
- 媒体类型(通常称为 Multipurpose Internet Mail Extensions 或 MIME 类型 )是一种标准,用来表示文档、文件或字节流的性质和格式。
- 意为:多用途的互联网邮件拓展
- MIME 类型:又称作
资源类型或媒体类型
mime 类型结构: [type]/[subType]
mime 类型结构: [type主类型种类]/[subType子类型格式]
例如: text/html text/css image/jpeg image/png application/json- HTTP 服务可以设置响应头 Content-Type 来表明响应体的 MIME 类型,浏览器会根据该类型决定如何处理资源
下面是常见文件资源对应的 mime 类型
| 文件扩展名 | MIME 类型 |
|---|---|
| html | text/html |
| css | text/css |
| js | text/javascript |
| png | image/png |
| jpg | image/jpeg |
| gif | image/gif |
| mp4 | video/mp4 |
| mp3 | audio/mpeg |
| json | application/json |
- 在现实项目中,是通过引入现成的处理模块完成设置响应资源的 MIME 类型,代替手敲node.js逻辑代码,不需要这样设置,了解即可
/**
* 需求:
* 创建一个 HTTP 服务,端口为 9000,满足如下需求
* GET /index.html 响应 page/index.html 的文件内容
* GET /css/app.css 响应 page/css/app.css 的文件内容
* GET /images/logo.png 响应 page/images/logo.png 的文件内容
*/
//导入 http 模块
const http = require('http');
const fs = require('fs');
const path = require('path');
//声明一个变量,等于一个对象,放入类型
let mimes = {
html: 'text/html',
css: 'text/css',
js: 'text/javascript',
png: 'image/png',
jpg: 'image/jpeg',
gif: 'image/gif',
mp4: 'video/mp4',
mp3: 'audio/mpeg',
json: 'application/json'
}
// 创建服务对象
const server = http.createServer((request, response) => {
// 获取请求url的路径
let { pathname } = new URL(request.url, 'http://127.0.0.1');
// 声明一个变量,定义为 “文件的绝对路径__dirname拼接'/page'文件夹路径”
// 这个变量,就是网站的根目录
let root = __dirname + '/page';
// 通过更改资源文件夹的路径,来变更网站的根目录
// let root = __dirname + '/../';
// 拼接文件路径,在网站的根目录基础上,再拼接上请求地址
let filePath = root + pathname;
//读取文件 fs 异步 API(还没学同步的错误处理)
fs.readFile(filePath, (err, data) => {
if (err) {
console.log(err);
//设置字符集
response.setHeader('content-type', 'text/html;charset=utf-8');
//如果出错,判断错误的代号,并相应返回对应的状态码和描述
response.statusCode = 500;
response.end('文件读取失败');
return;
}
// 在通过fs,完成读取文件后,再去设置响应头
// 由于响应头的参数值设置(第二个参数)不能写死(写死会导致类型获取混乱)
// 因此,需通过请求的文件后缀名,来获取对应的类型
// 不获取文件类型,浏览器有MIME嗅探功能,可以根据响应返回的内容,确认资源类型
//获取文件的后缀名,引入const path = require('path');,从下标1开始截取,去掉后缀前面的.点
let ext = path.extname(filePath).slice(1);
console.log(ext)
//获取后缀对应的类型
let type = mimes[ext];
if (type) {
//匹配到了
response.setHeader('content-type', type);
} else {
//没有匹配到,后缀不在mimes对象类型中,未知的资源类型,为下载的效果
response.setHeader('content-type', 'application/octet-stream');
}
//响应文件内容
response.end(data);
})
});
//监听端口, 启动服务
server.listen(9000, () => {
console.log('服务已经启动....')
});对于未知的资源类型,可以选择
application/octet-stream类型, 浏览器在遇到该类型的响应时,会对响应体内容进行独立存储,也就是我们常见的下载效果
设置响应资源的 MINE 类型时的字符集乱码问题
- 设置响应资源的 MINE 类型时,在设置的类型type类型值后面,插入charset=utf-8字符集,解决资源文件中因有中文而产生的乱码
- 网页字符集的设置方式有两个:
- 一个是HTML文件中的meta标签所设置的字符集charset,优先级低,可被覆盖
- 一个是设置响应头,优先级高
- index.html中的meta标签所设置的字符集charset,优先级低于响应头设置的字符集
- 网页引入的一些外部资源,如:css、js、图片,在设置响应时,是没有必要去设置字符集的
- 这些外部资源在加载进网页时,都会根据网页的字符集,对响应的结果作处理
- 通过调试发现,这些外部引入的单个资源,没有设置字符集,打开查看也是显示乱码,但在加载回主文件时会被主网页的字符集正确解析
- 因此,在获取后缀对应的类型,加上检测,当遇到的文件是html主网页文件时,type类型加上
type + ';charset=utf-8'字符集即可,也能覆盖掉meta标签所设置的字符集类型
/**
* 需求:
* 创建一个 HTTP 服务,端口为 9000,满足如下需求
* GET /index.html 响应 page/index.html 的文件内容
* GET /css/app.css 响应 page/css/app.css 的文件内容
* GET /images/logo.png 响应 page/images/logo.png 的文件内容
*/
//导入 http 模块
const http = require('http');
const fs = require('fs');
const path = require('path');
//声明一个变量,等于一个对象,放入类型
let mimes = {
html: 'text/html',
css: 'text/css',
js: 'text/javascript',
png: 'image/png',
jpg: 'image/jpeg',
gif: 'image/gif',
mp4: 'video/mp4',
mp3: 'audio/mpeg',
json: 'application/json'
}
// 创建服务对象
const server = http.createServer((request, response) => {
// 获取请求url的路径
let { pathname } = new URL(request.url, 'http://127.0.0.1');
// 声明一个变量,定义为 “文件的绝对路径__dirname拼接'/page'文件夹路径”
// 这个变量,就是网站的根目录
let root = __dirname + '/page';
// 通过更改资源文件夹的路径,来变更网站的根目录
// let root = __dirname + '/../';
// 拼接文件路径,在网站的根目录基础上,再拼接上请求地址
let filePath = root + pathname;
//读取文件 fs 异步 API(还没学同步的错误处理)
fs.readFile(filePath, (err, data) => {
if (err) {
console.log(err);
//设置字符集
response.setHeader('content-type', 'text/html;charset=utf-8');
//如果出错,判断错误的代号,并相应返回对应的状态码和描述
response.statusCode = 500;
response.end('文件读取失败');
return;
}
// 在通过fs,完成读取文件后,再去设置响应头
// 由于响应头的参数值设置(第二个参数)不能写死(写死会导致类型获取混乱)
// 因此,需通过请求的文件后缀名,来获取对应的类型
// 不获取文件类型,浏览器有MIME嗅探功能,可以根据响应返回的内容,确认资源类型
//获取文件的后缀名,引入const path = require('path');,从下标1开始截取,去掉后缀前面的.点
let ext = path.extname(filePath).slice(1);
console.log(ext)
//获取后缀对应的类型
let type = mimes[ext];
if (type) {
//匹配到了 text/html;charset=utf-8 优先级高于html中的meta标签
if (ext === 'html') {
response.setHeader('content-type', type + ';charset=utf-8');
} else { //css、js最后作用在html上会按照html的charset来解析
response.setHeader('content-type', type);
}
} else {
//没有匹配到,后缀不在mimes对象类型中,未知的资源类型,为下载的效果
response.setHeader('content-type', 'application/octet-stream');
}
//响应文件内容
response.end(data);
})
});
//监听端口, 启动服务
server.listen(9000, () => {
console.log('服务已经启动....')
});完善静态资源服务的错误处理
静态资源服务提供错误处理时,应根据不同的错误,返回不同的错误编号和错误提示
例如:在浏览器访问一个不存在的路径时,触发nodejs服务端打印错误信息
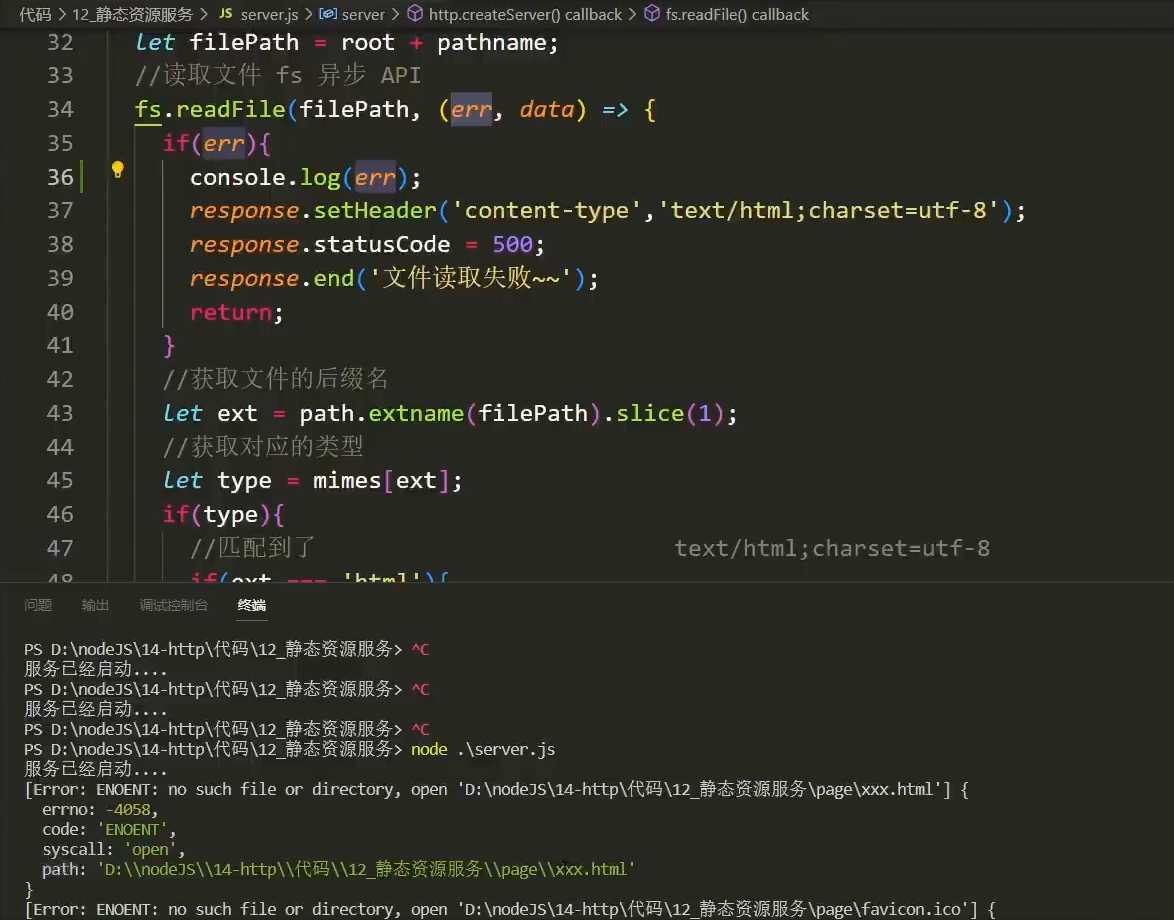
- 在资源找不到的时候,服务端应该给浏览器前端返回一个404的响应,通过状态码告知前端资源找不到,以返回一个正确的错误状态码和错误提示
- 在资源权限不对的时候,服务端应该给浏览器前端返回一个403的响应,错误提示 403 Forbidden 拒绝执行
- 在nodejs服务端后台打印出的错误信息,找到其中的错误代码code,复制到Node.js v23.5.0 文档 - error报错页中搜索,即可确认错误内容
- 一进页面请求http服务,就可以对请求的方法做判断
- 请求方法不对的状态码是405,默认未知错误的状态码是500
/**
* 需求:
* 创建一个 HTTP 服务,端口为 9000,满足如下需求
* GET /index.html 响应 page/index.html 的文件内容
* GET /css/app.css 响应 page/css/app.css 的文件内容
* GET /images/logo.png 响应 page/images/logo.png 的文件内容
*/
//导入 http 模块
const http = require('http');
const fs = require('fs');
const path = require('path');
//声明一个变量,等于一个对象,放入类型
let mimes = {
html: 'text/html',
css: 'text/css',
js: 'text/javascript',
png: 'image/png',
jpg: 'image/jpeg',
gif: 'image/gif',
mp4: 'video/mp4',
mp3: 'audio/mpeg',
json: 'application/json'
}
// 创建服务对象
const server = http.createServer((request, response) => {
// 一进页面请求http服务,就对请求的方法做判断
if (request.method !== 'GET') {
// 请求方法不对的状态码是405
response.statusCode = 405;
response.end('<h1>405 Method Not Allowed</h1>');
return;
}
// 获取请求url的路径
let { pathname } = new URL(request.url, 'http://127.0.0.1');
// 声明一个变量,定义为 “文件的绝对路径__dirname拼接'/page'文件夹路径”
// 这个变量,就是网站的根目录
let root = __dirname + '/page';
// 通过更改资源文件夹的路径,来变更网站的根目录
// let root = __dirname + '/../';
// 拼接文件路径,在网站的根目录基础上,再拼接上请求地址
let filePath = root + pathname;
//读取文件 fs 异步 API(还没学同步的错误处理)
fs.readFile(filePath, (err, data) => {
if (err) {
// 打印报错
console.log(err);
// 响应头放前,作一个统一的字符集设置
response.setHeader('content-type', 'text/html;charset=utf-8');
// 如果出错,判断错误的代号,并相应返回对应的状态码和描述
switch (err.code) {
case 'ENOENT':
response.statusCode = 404;
response.end('<h1>404 Not Found</h1>');
break;
case 'EPERM':
response.statusCode = 403;
response.end('<h1>403 Forbidden</h1>');
break;
// 默认未知错误
default:
response.statusCode = 500;
response.end('<h1>Internal Server Error</h1>');
}
return;
}
// 在通过fs,完成读取文件后,再去设置响应头
// 由于响应头的参数值设置(第二个参数)不能写死(写死会导致类型获取混乱)
// 因此,需通过请求的文件后缀名,来获取对应的类型
// 不获取文件类型,浏览器有MIME嗅探功能,可以根据响应返回的内容,确认资源类型
//获取文件的后缀名,引入const path = require('path');,从下标1开始截取,去掉后缀前面的.点
let ext = path.extname(filePath).slice(1);
console.log(ext)
//获取后缀对应的类型
let type = mimes[ext];
if (type) {
//匹配到了 text/html;charset=utf-8 优先级高于html中的meta标签
if (ext === 'html') {
response.setHeader('content-type', type + ';charset=utf-8');
} else { //css、js最后作用在html上会按照html的charset来解析
response.setHeader('content-type', type);
}
} else {
//没有匹配到,后缀不在mimes对象类型中,未知的资源类型,为下载的效果
response.setHeader('content-type', 'application/octet-stream');
}
//响应文件内容
response.end(data);
})
});
//监听端口, 启动服务
server.listen(9000, () => {
console.log('服务已经启动....')
});GET 和 POST 请求应用场景
向服务端发送 GET 请求的情况/应用场景:
- 在地址栏直接输入 url 访问
- 点击 a 链接
- link 标签引入 css
- script 标签引入 js
- video 与 audio 引入多媒体
- img 标签引入图片
- form 表单标签中的 method 为 get (不区分大小写)
- ajax 中的 get 请求
POST 请求的情况:
- form 标签中的 method 为 post(不区分大小写)
- AJAX 的 post 请求
GET和POST请求的区别
GET 和 POST 是 HTTP 协议请求的两种方式。
- 作用不同:
- GET 主要用来获取数据,POST 主要用来提交数据;(注,此为一般情况下的作用,也能POST获取GET新增数据)
- 参数位置:
- GET 带参数请求是将参数缀到 URL 之后,在地址栏中输入 url 访问网站就是 GET 请求,POST 带参数请求是将参数放到请求体中 (注:这只是默认的行为,GET也能设置请求体的,POST也能设置查询字符串参数)
- 安全性:
- POST 请求相对 GET 安全一些,因为在浏览器中,向服务器发GET请求时,参数会在浏览器地址栏中暴露,可能造成泄露,POST请求无法直接看;此处的安全是相对的,通过Fiddler抓包也还是能看到的,只是没有显式明文传参数
- 特点:
- GET 请求大小有限制,一般为 2K,而 POST 请求则没有大小限制